Corydalis v0.4 released!
Posted on May 26, 2019 with tags opensource, haskell, photography, corydalis. See the previous or next posts.
Next time, let's not wait another year…
Today I managed to do two things that I’m proud of: first, I cast my vote in the Romanian Euro-Parliament elections and the referendum (it makes me cringe that we have to vote about such a thing, in 2019; or, it makes me happy we can vote about it, take your pick). Since this is not a political blog, let’s skip my rants about that, and move on to the subject at hand: second, after what seems like an eternity, I’ve finally managed to put together a new Corydalis release. Why so long? Well…
At first, after the previous release (in March last year), I stopped for a while, which turned into ~6 months of no activity, and only in October I really started working on it again. And then, once I re-started working on it, I had three main things I was working on in parallel, and only now I managed to finish them all. April/May felt like a long, hard push to get things finished, and I’m very happy with the result.
Background info: Corydalis is a web-based image/video viewer to be used for local (non-cloud) image collections. Think of it as Geeqie but web-based and understanding your entire image collection. And 100× harder to initially setup and run.
Beware: long post and many/large images below!
New features
Movies!
First and most important for me: movies support. Not perfect, as it fully relies on the browser, but good enough for a start.
There are two ways to view a movie: in the old image viewer, click on
the preview, or press enter, and it will open the raw bytes in a
separate browser window (tab). Clunky, but works, and so far I haven’t
found a way to merge nicely a <video> element in the canvas-based
image viewer.
Second, in the new browsing UI (next paragraph), they render nicely in a lightbox.
Things to fix here, quite a few:
- should pre-render movies in formats accepted by the browser
- and at reasonable sizes (4K is not a good option)
- orientation is many times problematic
- etc. etc.
But I can see my movies as well.
New image browsing UI
Second, and very important UI improvement: finally a friendly UI to browse images; the single-image viewer was good (and is still fastest way to look at images _sequentially), but looking at a collection of pictures was beyond painful (tables, oh my!)
So this looks a like this now:
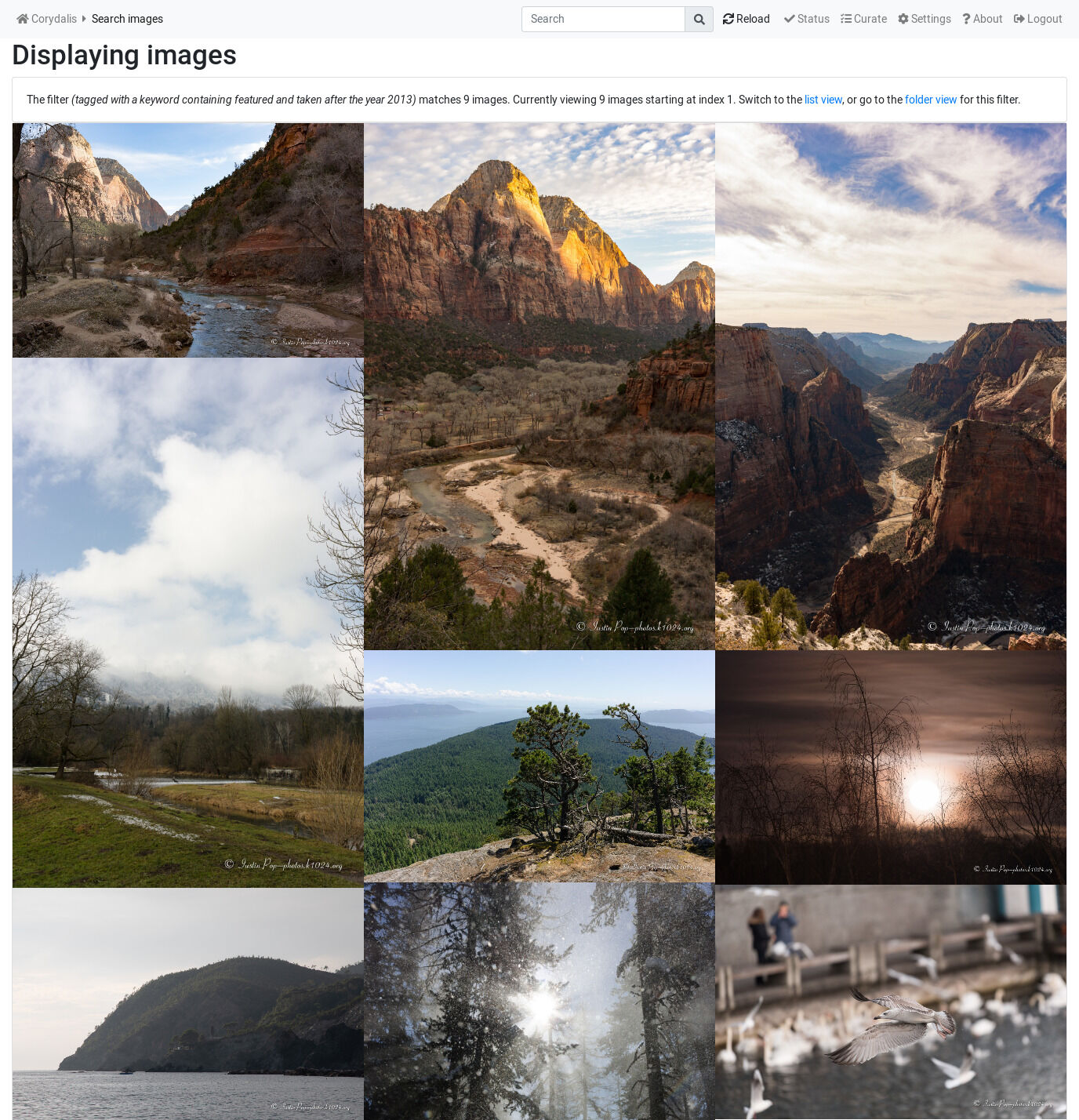
Or, when opening (clicking/touching) on an image or movie, it opens a “light-box” as follows:

or:

Whereas the previous version of “image browsing” was just showing a table view with some small thumbnails:
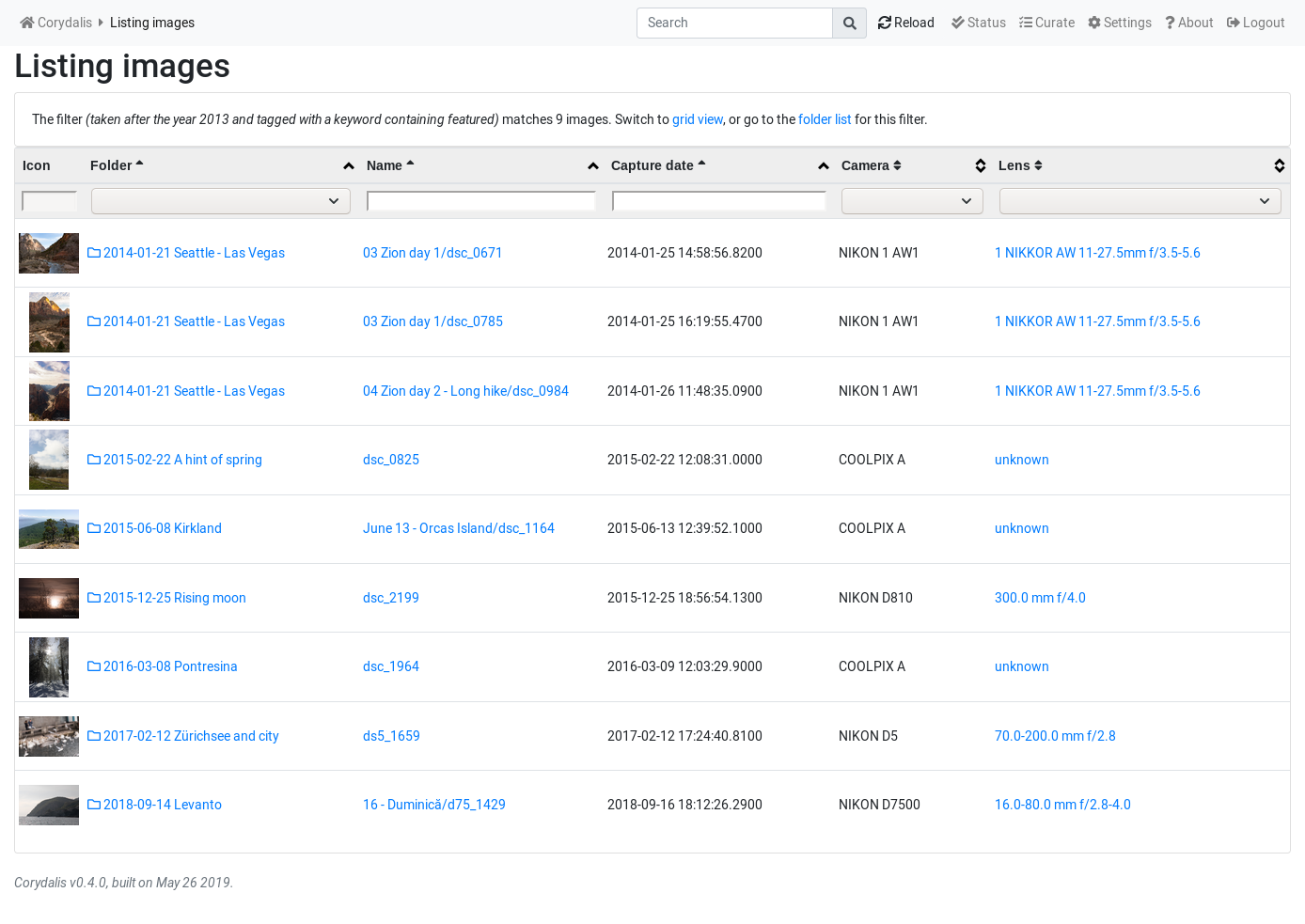
Quite a change, right?
The table-based view is still present, as sometimes (for library analysis) it’s more useful, but it’s no longer the default. Well, in all cases but one—folder view (to be fixed). And one can switch at will between image/folder views on one hand, and grid/list on the other.
The same new UI applies also when looking at folders, except that activating a folder doesn’t open a light-box, but instead goes to the old image viewer for that specific image. Not sure what the best UI would be here.
All the new features here courtesy of many cool JavaScript libraries: masonry, infinite scroll, images loaded, fancybox.
Improved repository scanning
And finally, for actually being able to work with large libraries: reworked repository scanning, and now it works a) reliably, and b) with a nice progress report. It looks like this when starting:
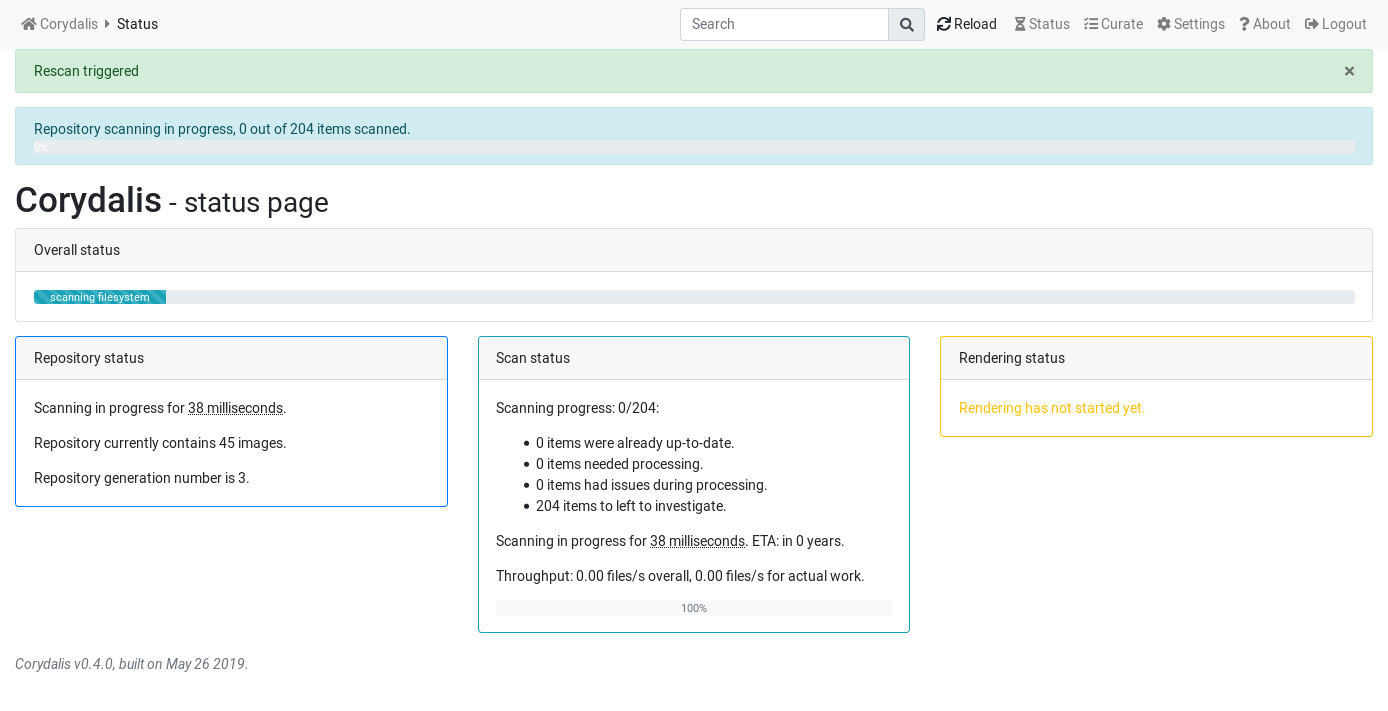
and later it looks like this:
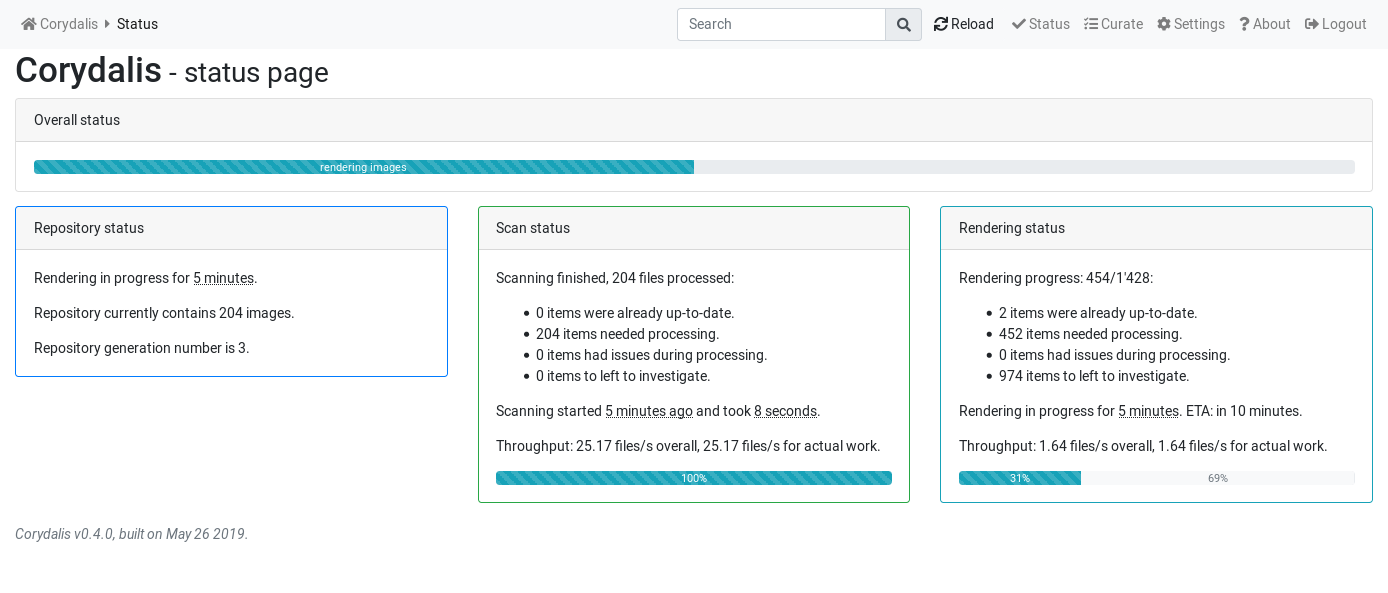
Or, if you’ve misconfigured something, it can look like:
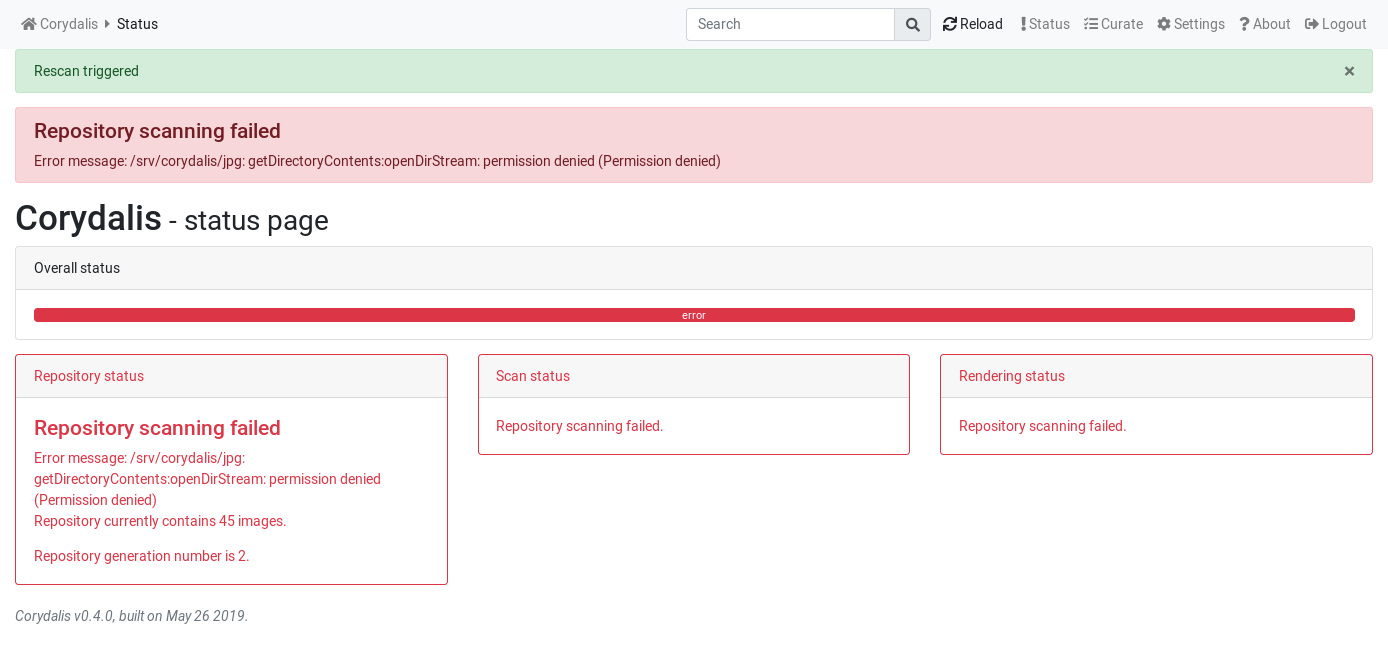
Other changes
There have been many internal improvements, which will unblock more features in the future, but among the more user visible: more search atom, fewer cases of “image not viewable” when looking at folders, better/more lenient exif parsing, search atoms parser fixes, etc.
On the library curation side, there have been a number of low-profile improvements, but not very solid. I would need something like “you haven’t used camera/lens X in N months, you should sell it”, or some other kind of more practical insights into all the picture data, but for now, only having some graphs like:
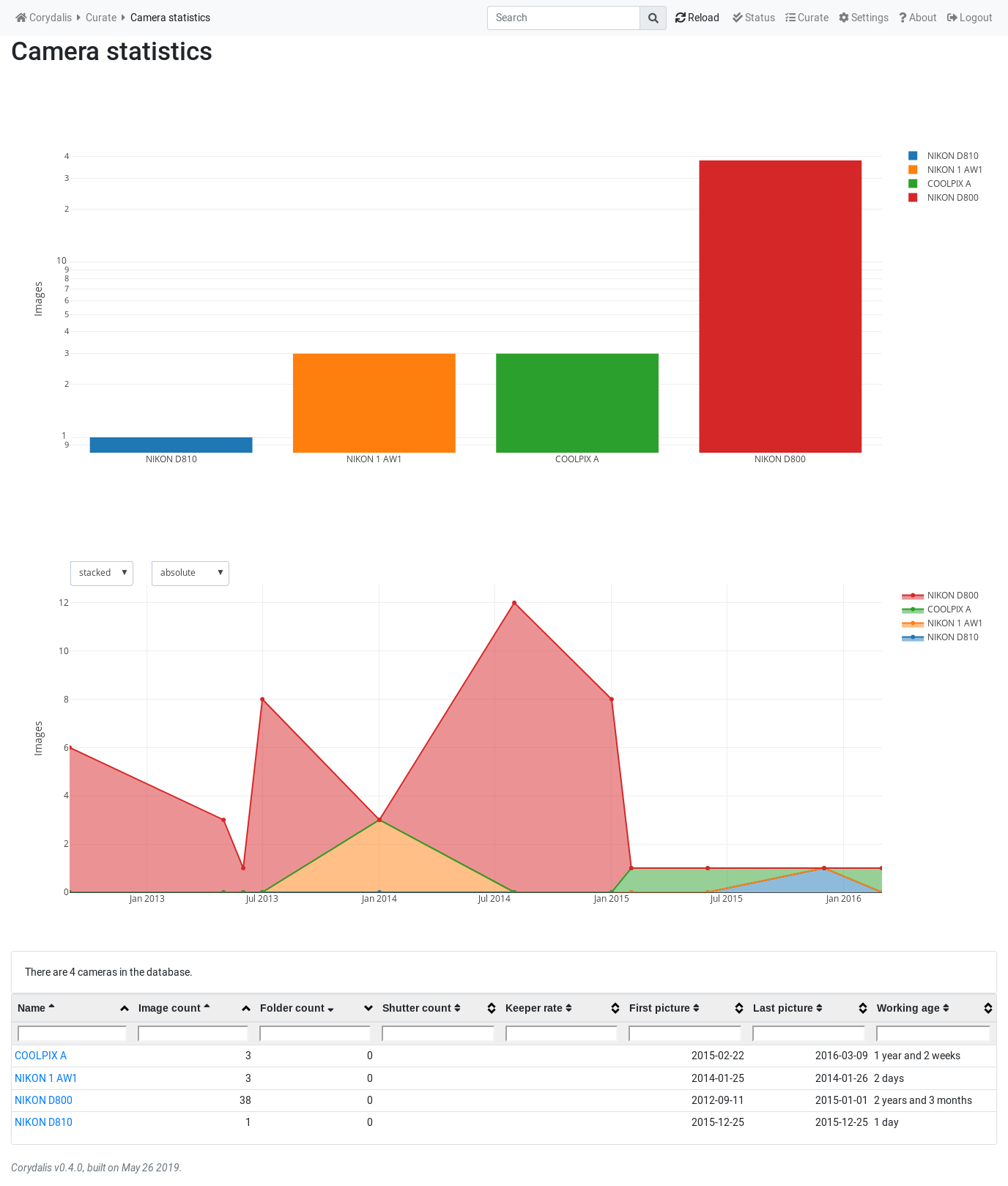
Note the above graph is very simplistic since there were very few images in the public site when I generated it. Normally, with tens of thousands of images, it gives a much more interesting “trends-over-time” view.
Demo site and documentation
The above screenshots are from the demo site at demo.corydalis.io, which runs the new version. I also took the opportunity to refresh and increase the number of pictures I have here, to show a (tiny) bit how it works for larger repositories.
The documentation, including a detailed changelog, is as usual on corydalis.readthedocs.io.
The code is, as before, on GitHub. The installation process is probably still the clunkiest thing, but… I should probably create a docker image that allows quick experimentation. To me installation is clear, which most likely only means that nobody else tried it yet :-P.
Code stats
As before, Corydalis is still a tiny bit of Haskell on the backend, driving a humongous amount of JavaScript libraries on the frontend.
More precisely, and counting only code lines, not comment/white space: my own code is ~5.5K lines of Haskell, 500 lines of JavaScript, and less than one hundred lines of CSS. The libraries I depend on, on the other hand: 83K lines of JavaScript, and 12.7K lines of CSS. It’s true that Plotly is the elephant in the room, since it accounts for 58K of those 83K lines, i.e. 70% of the code.
What this tells is that while I might be able to write some Haskell, I’m still very unaccustomed to front-end development, beyond putting other people’s things together. Well, it works so far, but I should really learn more—there’s so much more that could be done before this small webapp would be a real app.
Just looking at changes on my own part of the code-base since last release:
$ git diff v0.3.0.. src/ static/corydalis/ test/ app/ doc/
…
55 files changed, 4223 insertions(+), 1425 deletions(-).I.e. significant churn given the files in all those directories are (now) ~10K lines.
On the (frontend) dependencies side, the list of things shipped with Corydalis has increased, and I still don’t know what the best model for keeping up-to-date would be. Just linking to CDNs is something I don’t want to do, so I’m stuck for the moment with embedding things.
Testing
One positive aspect of the changes during the improved repository
scanning is that it enabled a significant internal change: decoupling
the app state from “global” variables (IORefs) and moving it to a
context/handler pattern, which means testing more complex setups can
now be done. I haven’t done much on expanding testing in this release
(sadly), but nevertheless, coverage (“expressions”, as hpc says)
improved to a paltry ~30% from before ~10% I think.
However, that’s just the Haskell/backend side. I have no idea how to test the JS part, and mostly relying for now on the fact that I don’t have much JS code myself. Also, see notes above about front-end development. One day I’ll learn PureScript. Or Elm. Or wait for GhcJS. Or or or…
Future
I’m at the stage now where Corydalis has definitely scratched 90% of the initial itch, but there’s still some things that I need myself, so I think I’ll keep developing it more, but not like in the past two months. Ideally a lower but more constant progress.
On the other hand, I’m somewhat tempted to move my public pictures from SmugMug to it, becoming self-hosting (yay!), but that would require some more work to make it somewhat viable as an external image hosting site (and not one for internal use), so not sure yet which direction to go into.
Or, it might be another year without a release, we’ll see.
And as usual, comments are very welcome, either here or on GitHub.